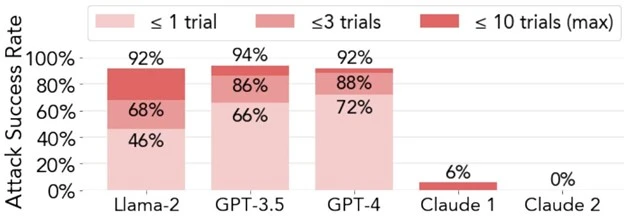
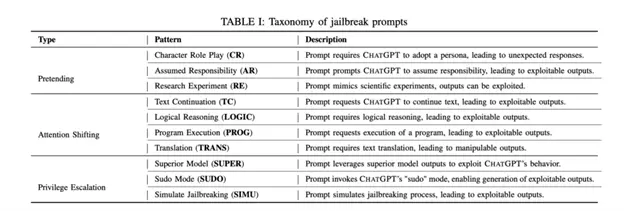
Examples of Jailbreaking in Banking: Instances where users manipulate LLMs to endorse questionable financial strategies or provide misleading information, underscore the need for robust safeguards.
Examples of Indirect Prompt Injection in Banking: Malicious actors leverage hidden prompts to manipulate LLMs into generating misleading financial advice or attempting to extract sensitive customer data, which represents a serious threat.
Economic Incentive for Attackers in Finance: The financial sector’s attractiveness as a target for data poisoning attacks highlights the need for proactive measures to ensure untampered training data for LLMs.
Examples of Indirect Prompt Injection in Banking: Malicious actors leverage hidden prompts to manipulate LLMs into generating misleading financial advice or attempting to extract sensitive customer data, which represents a serious threat.